
This article originally appeared Aug. 21, 2020 on the APNIC blog.
Introduction
Chromium is an open-source software project that forms the foundation for Google’s Chrome web browser, as well as a number of other browser products, including Microsoft Edge, Opera, Amazon Silk, and Brave. Since Chrome’s introduction in 2008, Chromium-based browsers have steadily risen in popularity and today comprise approximately 70% of the market share.1
Chromium has, since its early days, included a feature known as the omnibox. This is where users may enter either a web site name, URL, or search terms. But the omnibox has an interface challenge. The user might enter a word like “marketing” that could refer to both an (intranet) web site and a search term. Which should the browser choose to display? Chromium treats it as a search term, but also displays an infobar that says something like “did you mean http://marketing/?” if a background DNS lookup for the name results in an IP address.
At this point, a new issue arises. Some networks (e.g., ISPs) utilize products or services designed to intercept and capture traffic from mistyped domain names. This is sometimes known as “NXDomain hijacking.” Users on such networks might be shown the “did you mean” infobar on every single-term search. To work around this, Chromium needs to know if it can trust the network to provide non-intercepted DNS responses.
Chromium Probe Design
Inside the Chromium source code there is a file named intranet_redirect_detector.c. The functions in this file attempt to load three URLs whose hostnames consist of a randomly generated single-label domain name, as shown in Figure 1 below.

This code results in three URL fetches, such as http://rociwefoie/, http://uawfkfrefre/, and http://awoimveroi/, and these in turn result in three DNS lookups for the random host names. As can be deduced from the source code, these random names are 7-15 characters in length (line 151) and consist of only the letters a-z (line 153). In versions of the code prior to February 2014, the random names were always 10 characters in length.
The intranet redirect detector functions are executed each time the browser starts up, each time the system/device’s IP address changes, and each time the system/device’s DNS configuration changes. If any two of these fetches resolve to the same address, that address is stored as the browser’s redirect origin.
Identifying Chromium Queries
Nearly any cursory glance at root name server traffic will exhibit queries for names that look like those used in Chromium’s probe queries. For example, here are 20 sequential queries received at an a.root-servers.net instance:
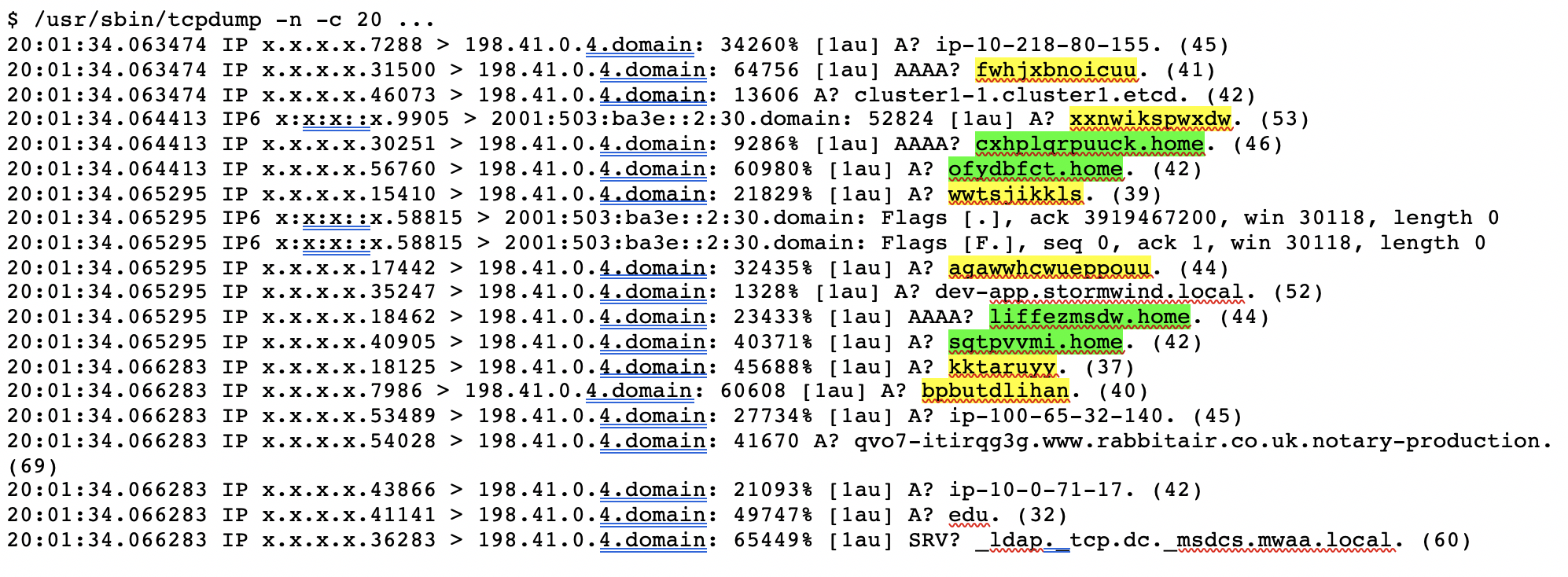
In this brief snippet of data, we can see six queries (yellow highlight) for random, single-label names, and another four (green highlight) with random first labels followed by an apparent domain search suffix. These match the pattern from the Chromium source code, being 7-15 characters in length and consisting of only the letters a-z.
To characterize the amount of Chromium probe traffic in larger amounts of data (i.e., covering a 24-hour period), we tabulate queries based on the following attributes:
- Response code (NXDomain or NoError)
- Popularity of the leftmost label
- Length of the leftmost label
- Characters used in the leftmost label
- Number of labels in the full query name
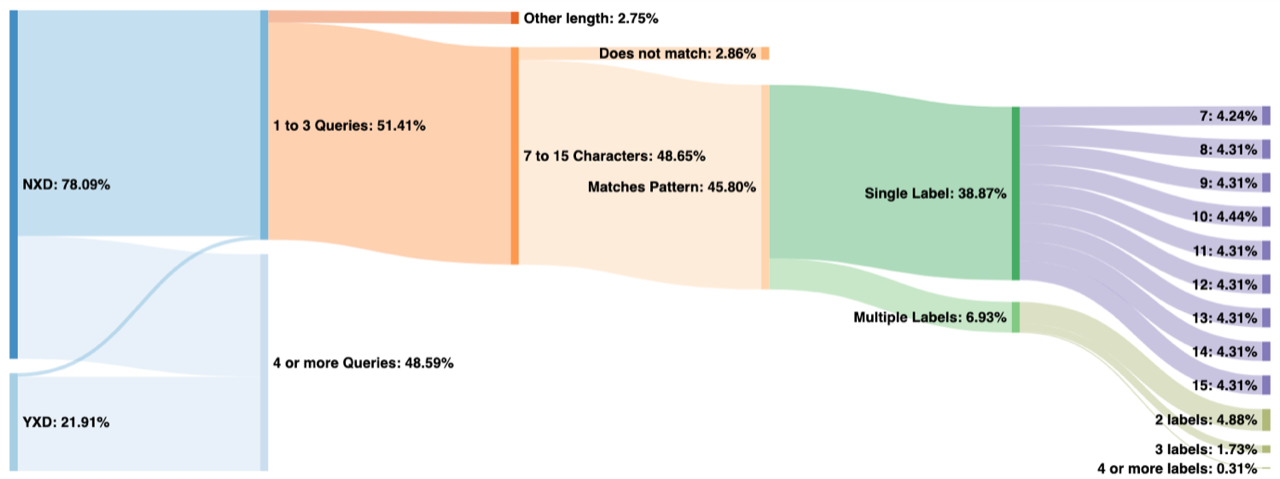
Figure 2 shows a classification of data from a.root-servers.net on May 13, 2020. Here we can see that 51% of all queried names were observed fewer than four times in the 24-hour period. Of those, nearly all were for non-existent TLDs, although a very small amount come from the existing TLDs (labeled “YXD” on the left). This small sliver represents either false positives or Chromium probe queries that have been subject to domain suffix search appending by stub resolvers or end user applications.
Of the 51% observed fewer than four times, all but 2.86% of those have a first label between 7 and 15 characters in length (inclusive). Furthermore, most of those match the pattern consisting of only a-z characters (case insensitive), leaving us with 45.80% of total traffic on this day that appears to be from Chromium probes.
From there we break down the queries by number of labels and length of the first label. Note that label lengths, on the far right of the graph, have a very even distribution, except for 7 and 10 characters. Labels with 10 characters are more popular because older versions of Chromium generated only 10-character names. We believe that 7 is less popular due to the increased probability of collisions in only 7 characters, which can increase the query count to above our threshold of three.
Longitudinal Analysis
Next, we turn our attention to an analysis of how the total root traffic percentage of Chromium-like queries has changed over time. We use two data sets in this analysis: data from DNS-OARC’s “Day In The Life” (DITL) collections, and Verisign’s data for a.root-servers.net and j.root-servers.net.
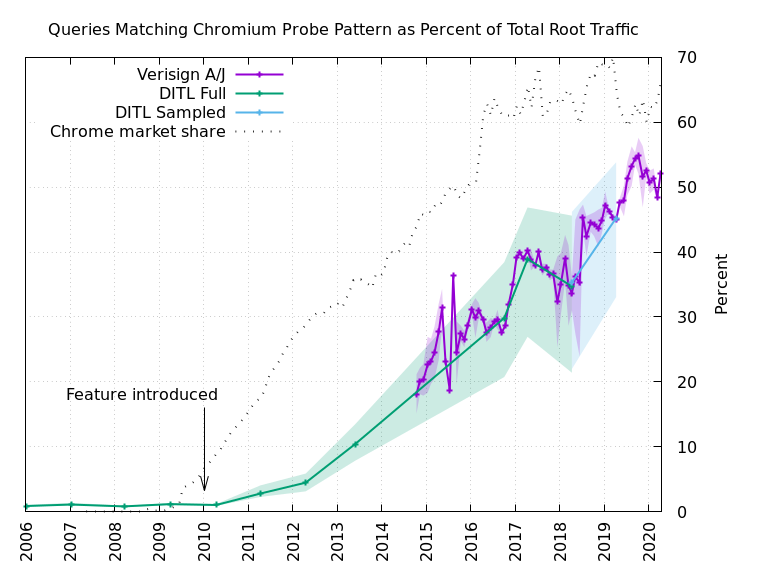
Figure 3 shows the results of the long-term analysis. We were able to analyze the annual DITL data from 2006-2014, and from 2017-2018, labeled “DITL Full” in the figure. The 2015-2016 data was unavailable on the DNS-OARC systems. The 2019 dataset could not be analyzed in full due to its size, so we settled for a sampled analysis instead, labeled “DITL Sampled” in Figure 3. The 2020 data was not ready for analysis by the time our research was done.
In every DITL dataset, we analyzed each root server identity (“letter”) separately. This produces a range of values for each year. The solid line shows the average of all the identities, while the shaded area shows the range of values.
To fill in some of the DITL gaps we used Verisign’s own data for a.root-servers.net and j.root-servers.net. Here we selected a 24-hour period for each month. Again, the solid line shows the average and the shaded area represents the range.
The figure also includes a line labeled “Chrome market share” (note: Chrome, not Chromium-based browsers) and a marker indicating when the feature was first added to the source code. Note, there are some false positive Chromium-like queries observed in the DITL data prior to introduction of the feature, comprising about 1% of the total traffic, but in the 10+ years since the feature was added, we now find that half of the DNS root server traffic is very likely due to Chromium’s probes. That equates to about 60 billion queries to the root server system on a typical day.
Concluding Thoughts
The root server system is, out of necessity, designed to handle very large amounts of traffic. As we have shown here, under normal operating conditions, half of the traffic originates with a single library function, on a single browser platform, whose sole purpose is to detect DNS interception. Such interception is certainly the exception rather than the norm. In almost any other scenario, this traffic would be indistinguishable from a distributed denial of service (DDoS) attack.
Could Chromium achieve its goal while only sending one or two queries instead of three? Are other approaches feasible? For example, Firefox’s captive portal test uses delegated namespace probe queries, directing them away from the root servers towards the browser’s own infrastructure. While technical solutions such as Aggressive NSEC Caching (RFC 8198), Qname Minimization (RFC 7816), and NXDomain Cut (RFC 8020) could also significantly reduce probe queries to the root server system, these solutions require action by recursive resolver operators, who have limited incentive to deploy and support these technologies.
This piece was co-authored by Matt Thomas, Distinguished Engineer in Verisign’s CSO Applied Research division.
1 https://www.w3counter.com/trends


