
Since we published our second SSR report a few weeks back, recently updated with revision 1.1, we’ve been taking a deeper look at queries to the root servers that elicit “Name Error,” or NXDomain responses and figured we’d share some preliminary results.
Not surprisingly, promptly after publication of the Interisle Consulting Group’s Name Collision in the DNS report, a small number of the many who are impacted are aiming to discredit the report. While we believe it is not comprehensive and much more work needs to be done, it is a good start. We commend the Interisle folk for their efforts, particularly given the constrained dataset and timeframe to which they were captive. As for discrediting the report, it has been suggested that a significant portion of the queries that result in collisions with applied-for gTLDs at the root are largely a consequence of the intended or existent new gTLD applications themselves, and (of course) the associated community measurement and verification of the [non-]existence of those strings delegated as TLDs in the root. Some have even gone so far as to allude to “tampering” or gaming of the measurement data used by the Interisle Consulting Group to conduct their naming collisions study.
In fairness, I suppose there’s some clever adaptation here of how Heisenberg’s Uncertainty Principle could be applied to observations of applied-for new gTLD queries at the root, although I don’t think it’s quite as profound as professed. Furthermore, I suspect that an astute malicious actor could indeed attempt to influence measurement data via surgically manipulating query streams during collection periods, although I also suspect there are some mechanisms that could be used to detect such manipulation. Indeed, we took the precautionary step of quantifying “spread,’’ in order to verify cases where queries came from distributed client sets.
Irrespective of all of this, I do not believe that volumetric analysis of queries observed at the root is itself sufficient to gauge risks posed by new gTLDs. I believe there are many other dependent and external variables that likely serve as better indicators and those must be considered in any comprehensive risk analysis – acuteness is key!
Additionally, I do not believe that the current short-lived observations afforded from a subset of the root server system in the DITL data (as currently provided) are sufficient. As a matter of fact, this is precisely the reason why recommendations related to early warning and instrumentation capabilities across the root server system itself (before delegations are made) has been recommended since at least the Scaling the Root studies of 2009, and numerous SSAC recommendations (e.g., SAC045, SAC046, SAC059) thereafter. Lack of implementation of those recommendations has also been one key focus of Verisign security and stability concerns over the past six months. If the proper measurement apparatus doesn’t exist, then forewarning potentially impacted parties (as has also been recommended for over three years) is going to be, err.., problematic. I suspect this is why ICANN now proposes simply shifting that responsibility, liability, and accompanying operational burden to registry operators in their belated New gTLD Collision Risk Mitigation Proposal, a tactic that wholly perplexes me!
Nonetheless, I continue to believe that a community-vetted risk matrix and systematic application accompanying longitudinal study and analysis is the proper way to derive sound and defensible conclusions and progress in a safe and secure manner. Further, the express prioritization for development of early warning and instrumentation capability across the root server system, and resourcing to support that analysis, is critical. Until then, we’ll continue to play the hand we’re dealt, cognizant of the constraints.
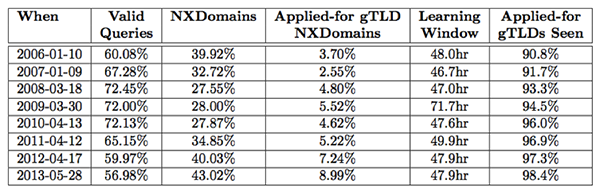
Table 1 illustrates applied-for gTLDs observed in queries to the root during the DITL collection windows over the past eight years. Even at the very lowest level in 2006, ~90.8% of the applied-for strings were observed in the TLD position in queries during just the relatively short DITL collection window alone. Note that there continues to be varying levels of coverage and participation in the DITL exercises even today. Furthermore, and in contrast to our previous observations, none of these DITL windows actually observed 100% of the applied-for strings, and as previously indicated, it took nearly six days of observation across both the a and j root servers that Verisign operates in order to see 100% of the applied-for strings.

One of the key observations here is that the historical trend indicates that there has been a longstanding footprint of queries for the current set of applied-for strings. The measurements also suggest that not all applied-for strings are immediately visible in query traffic to the DNS root that is provided in the DITL data collection windows throughout this timeframe. Figure 1 provides some additional illustration of the data since 2007, by plotting the new and re-observed applied-for string observations, using the 2006 DITL collection period to bootstrap a baseline. As you can see, most of the applied-for strings, nearly 91%, have been observed from year-to-year during the short DITL collection period since as far back as 2006. In 2013 queries were observed for 98.4% of the applied-for strings, some 96.95% of which had been seen in previous years as well.
The key takeaway here is that virtually all applied-for gTLD queries in any given year’s DITL data have been seen in a previous DITL window – suggesting there’s little new kinds of misconfiguration in the system, just more dependence on the Internet (and inadvertently, existence or non-existence of a given string delegated as a TLD in the root). That said, I still don’t believe that simply observing queries at the root, or absence thereof, itself constitutes risks from delegation. Observations and volume are certainly two sets of attributes to be considered, but the community needs to agree upon which attributes constitute risk and why. Only then we can begin to perform systematic risk analysis and accept, mitigate, transfer, or avoid the risks associated with each individual string, and a cohesive measurement apparatus (i.e., early warning and instrumentation capability across the root server system) is a requisite to do this properly.
Finally, most of what ICANN and others are considering here at the moment isn’t actually risk, where it’s assumed the ability and enough information exists to qualify impact. It is actually uncertainty, where because of lack of implementation of previous recommendations ICANN is currently not capable or qualified to make value judgments as to what actually constitutes risk, nor to measure and make informed decisions about where said risk may or may not exist.


