This is the fourth in a multi-part series on cryptography and the Domain Name System (DNS).
One of the “key” questions cryptographers have been asking for the past decade or more is what to do about the potential future development of a large-scale quantum computer.
This is the third in a multi-part blog series on cryptography and the Domain Name System (DNS).
In my last post, I looked at what happens when a DNS query renders a “negative” response – i.e., when a domain name doesn’t exist. I then examined two cryptographic approaches to handling negative responses: NSEC and NSEC3. In this post, I will examine a third approach, NSEC5, and a related concept that protects client information, tokenized queries.
This is the second in a multi-part blog series on cryptography and the Domain Name System (DNS).
In my previous post, I described the first broad scale deployment of cryptography in the DNS, known as the Domain Name System Security Extensions (DNSSEC). I described how a name server can enable a requester to validate the correctness of a “positive” response to a query — when a queried domain name exists — by adding a digital signature to the DNS response returned.
This is the first in a multi-part blog series on cryptography and the Domain Name System (DNS).
As one of the earliest protocols in the internet, the DNS emerged in an era in which today’s global network was still an experiment. Security was not a primary consideration then, and the design of the DNS, like other parts of the internet of the day, did not have cryptography built in.
A year ago, under the leadership of the Internet Corporation for Assigned Names and Numbers (ICANN), the internet naming community completed the first-ever rollover of the cryptographic key that plays a critical role in securing internet traffic worldwide. The ultimate success of that endeavor was due in large part to outreach efforts by ICANN and Verisign which, when coupled with the tireless efforts of the global internet measurement community, ensured that this significant event did not disrupt internet name resolution functions for billions of end users.
March 22, 2019 saw the completion of the final important step in the Key Signing Key (KSK) rollover – a process which began about a year and half ago. What may be less well known is that post rollover, and until just a couple days ago, Verisign was receiving a dramatically increasing number of root DNSKEY queries, to the tune of 75 times higher than previously observed, and accounting for ~7 percent of all transactions at the root servers we operate.
Recent events1,2 have shown the threat of domain hijacking is very real; however, it is also largely preventable. As Verisign previously noted3, there are many security controls that registrants can utilize to help strengthen their security posture. Verisign would like to reiterate this advice within the context of the recent domain hijacking reports.
Currently scheduled for October 11, 2018, the Internet Corporation for Assigned Names and Numbers (ICANN) plans to change the cryptographic key that helps to secure the internet’s Domain Name System (DNS) by performing a Root Zone Domain Name System Security Extensions (DNSSEC) key signing key (KSK) rollover.
The Domain Name System (DNS) is the cornerstone of communication for the internet. Navigating to the sites you access every day often starts with a DNS request. Cybercriminals recognize the value of DNS and may look for ways to abuse improperly secured DNS to compromise its uptime, integrity or overall response efficacy—which makes DNS an important area for enforcing security and protecting against threats.
On Sept. 27, Internet Corporation of Assigned Names and Numbers (ICANN) announced that the first root zone Key Signing Key (KSK) rollover – originally scheduled to take place on Oct. 11 – will be postponed. Although this was certainly a difficult decision, we fully agree that erring on the side of caution is the best approach to take. In this blog post, I want to explain some of the involvement Verisign has had in KSK rollover preparations, as well as some of the recently available research opportunities which generated data that we shared with ICANN related to this decision.
Every Domain Name System Security Extensions (DNSSEC) validator on the internet requires a Trust Anchor. This is a key, or a hash of a key, that corresponds to the root zone KSK(s). Whenever a KSK rollover occurs, validators need to update their trust anchors to include the new key. The design of DNSSEC includes a mechanism, commonly referred to as RFC 5011, whereby validators can automatically update their trust anchors. Because there has never been an operational root KSK rollover, RFC 5011 has never been tested in production. In assessing rollover preparedness, our folks, as well as others, began to identify and work with the community on correcting some implementation and configuration bugs with RFC 5011.
One missing piece, however, was a way to tell whether or not a population of DNSSEC validating resolvers had successfully updated their trust anchors. That’s why, in late 2015, I began writing an Internet Draft that proposed a way for validators to self-report their trust anchor set. This document, titled “Signaling Trust Anchor Knowledge in DNSSEC,” was adopted by the Internet Engineering Task Force’s (IETF) DNS-OPS working group, refined with some co-authors from Google and ICANN, as well as review from the working group, and published in April of this year as RFC 8145.
For more information on RFC 8145 key tag signals, please refer to my presentation to the Fall 2017 DNS-OARC meeting.
At the time that the RFC was published, I thought it was probably too late to have any impact on the 2017 KSK rollover, but would certainly be informative for any subsequent rollovers. However, I was pleased to learn that Internet Systems Consortium (ISC) implemented the draft specification of this protocol in their BIND software in mid-2016, and it was slowly being deployed as people updated their software. NLnet Labs also implemented RFC 8145 in their Unbound software in mid 2017, although the feature was not enabled by default.
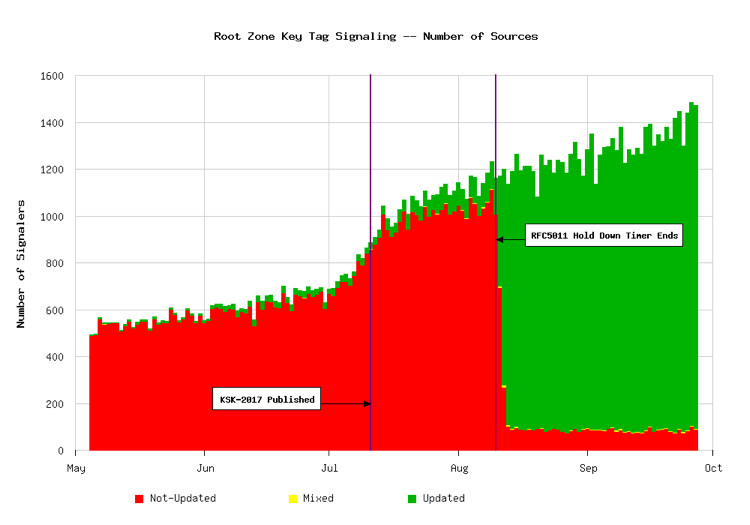
The “key tag signals” from these validators are sent to the root name servers. Beginning in May, I began looking at the data sent to Verisign’s A-root and J-root in anticipation of the rollover. Figure 1, shows the number of sources sending signals over time. The red bars represent validators reporting only the old KSK. Green represents validators reporting an updated trust anchor set (i.e., both the old and the new KSK). The small amount of yellow areas on the plot represent sources that sent mixed signals.
Figure 1. Key Tag signaling data.
As shown in the figure, the new KSK was first published in the root zone on July 11. Some signalers already indicated they had an updated trust anchor before then, however, more importantly, many of them had indicated they had not. These are validators that were either updated manually, or perhaps through a software update. There is a dramatic drop in “Not-Updated” signals beginning on Aug. 10, which corresponds to the end of the RFC 5011 “Hold Down Timer,” or 30 days after publication of the new key. This is good evidence that RFC 5011 worked for many validators.
What’s troubling, however, is the lingering amount of “Not-Updated” signals throughout the remainder of August and September. These validators appear to still have only the old KSK and are not accepting the new KSK into their trust anchor set. These represent six to eight percent of the population providing data, a figure we first shared with ICANN in late August. If the rollover was not postponed, these validators using only the old KSK would fail to resolve any domain names on Oct. 11, until their configurations were corrected.
Fortunately, the KSK Rollover Operational Implementation Plan easily accommodates the necessity to back out or postpone the progress of the rollover. The ability to do so was designed from the start and there is no urgent need to change the key from a cryptographic or security operations point of view. Rather than a zone whose key set is signed by the new KSK on Oct. 11, as ICANN has conveyed, we plan to continue publishing the root zone in its current DNSSEC configuration for the next calendar quarter. ICANN DNS expert and VP of Research, Matt Larson, penned a message to the DNS operations community, available here, which provides more information of the KSK Rollover Project from their perspective.
We were pleased with ICANN’s decision to postpone the KSK rollover in light of this data, which provides a known lower-bound of potential breakage that may occur as a result of the planned KSK rollover. We remain committed to working with ICANN and the community to prepare for these important changes, to help better understand why some validators have not updated their trust anchors, and assist in further community and relying party outreach efforts, all towards helping to minimize negative impacts when the KSK rollover occurs.