Currently scheduled for October 11, 2018, the Internet Corporation for Assigned Names and Numbers (ICANN) plans to change the cryptographic key that helps to secure the internet’s Domain Name System (DNS) by performing a Root Zone Domain Name System Security Extensions (DNSSEC) key signing key (KSK) rollover.
On Sept. 27, Internet Corporation of Assigned Names and Numbers (ICANN) announced that the first root zone Key Signing Key (KSK) rollover – originally scheduled to take place on Oct. 11 – will be postponed. Although this was certainly a difficult decision, we fully agree that erring on the side of caution is the best approach to take. In this blog post, I want to explain some of the involvement Verisign has had in KSK rollover preparations, as well as some of the recently available research opportunities which generated data that we shared with ICANN related to this decision.
Every Domain Name System Security Extensions (DNSSEC) validator on the internet requires a Trust Anchor. This is a key, or a hash of a key, that corresponds to the root zone KSK(s). Whenever a KSK rollover occurs, validators need to update their trust anchors to include the new key. The design of DNSSEC includes a mechanism, commonly referred to as RFC 5011, whereby validators can automatically update their trust anchors. Because there has never been an operational root KSK rollover, RFC 5011 has never been tested in production. In assessing rollover preparedness, our folks, as well as others, began to identify and work with the community on correcting some implementation and configuration bugs with RFC 5011.
One missing piece, however, was a way to tell whether or not a population of DNSSEC validating resolvers had successfully updated their trust anchors. That’s why, in late 2015, I began writing an Internet Draft that proposed a way for validators to self-report their trust anchor set. This document, titled “Signaling Trust Anchor Knowledge in DNSSEC,” was adopted by the Internet Engineering Task Force’s (IETF) DNS-OPS working group, refined with some co-authors from Google and ICANN, as well as review from the working group, and published in April of this year as RFC 8145.
For more information on RFC 8145 key tag signals, please refer to my presentation to the Fall 2017 DNS-OARC meeting.
At the time that the RFC was published, I thought it was probably too late to have any impact on the 2017 KSK rollover, but would certainly be informative for any subsequent rollovers. However, I was pleased to learn that Internet Systems Consortium (ISC) implemented the draft specification of this protocol in their BIND software in mid-2016, and it was slowly being deployed as people updated their software. NLnet Labs also implemented RFC 8145 in their Unbound software in mid 2017, although the feature was not enabled by default.
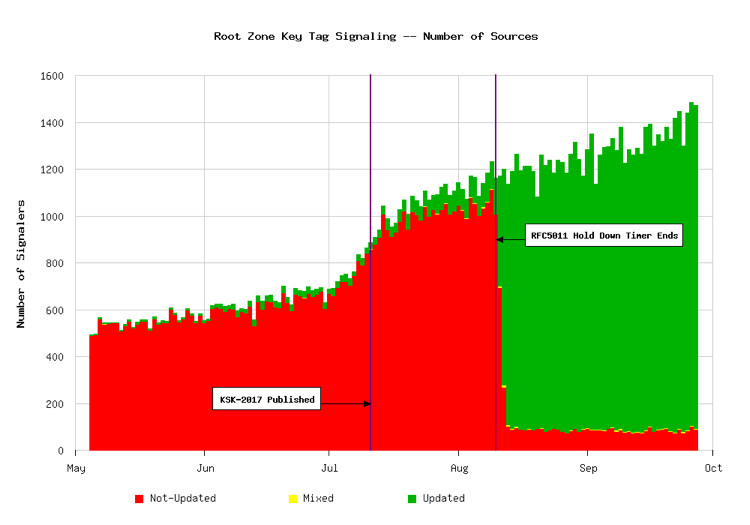
The “key tag signals” from these validators are sent to the root name servers. Beginning in May, I began looking at the data sent to Verisign’s A-root and J-root in anticipation of the rollover. Figure 1, shows the number of sources sending signals over time. The red bars represent validators reporting only the old KSK. Green represents validators reporting an updated trust anchor set (i.e., both the old and the new KSK). The small amount of yellow areas on the plot represent sources that sent mixed signals.
Figure 1. Key Tag signaling data.
As shown in the figure, the new KSK was first published in the root zone on July 11. Some signalers already indicated they had an updated trust anchor before then, however, more importantly, many of them had indicated they had not. These are validators that were either updated manually, or perhaps through a software update. There is a dramatic drop in “Not-Updated” signals beginning on Aug. 10, which corresponds to the end of the RFC 5011 “Hold Down Timer,” or 30 days after publication of the new key. This is good evidence that RFC 5011 worked for many validators.
What’s troubling, however, is the lingering amount of “Not-Updated” signals throughout the remainder of August and September. These validators appear to still have only the old KSK and are not accepting the new KSK into their trust anchor set. These represent six to eight percent of the population providing data, a figure we first shared with ICANN in late August. If the rollover was not postponed, these validators using only the old KSK would fail to resolve any domain names on Oct. 11, until their configurations were corrected.
Fortunately, the KSK Rollover Operational Implementation Plan easily accommodates the necessity to back out or postpone the progress of the rollover. The ability to do so was designed from the start and there is no urgent need to change the key from a cryptographic or security operations point of view. Rather than a zone whose key set is signed by the new KSK on Oct. 11, as ICANN has conveyed, we plan to continue publishing the root zone in its current DNSSEC configuration for the next calendar quarter. ICANN DNS expert and VP of Research, Matt Larson, penned a message to the DNS operations community, available here, which provides more information of the KSK Rollover Project from their perspective.
We were pleased with ICANN’s decision to postpone the KSK rollover in light of this data, which provides a known lower-bound of potential breakage that may occur as a result of the planned KSK rollover. We remain committed to working with ICANN and the community to prepare for these important changes, to help better understand why some validators have not updated their trust anchors, and assist in further community and relying party outreach efforts, all towards helping to minimize negative impacts when the KSK rollover occurs.
A few weeks ago, on Oct. 1, 2016, Verisign successfully doubled the size of the cryptographic key that generates Domain Name System Security Extensions (DNSSEC) signatures for the internet’s DNS root zone. With this change, root zone Domain Name System (DNS) responses can be fully validated using 2048-bit RSA keys. This project involved work by numerous people within Verisign, as well as collaborations with the Internet Corporation for Assigned Names and Numbers (ICANN), Internet Assigned Numbers Authority (IANA) and National Telecommunications and Information Administration (NTIA).
As I mentioned in my previous blog post, the root zone originally used a 1024-bit RSA key for zone signing. In recent years the internet community transitioned away from keys of this size for SSL and there has been pressure to also move away from 1024-bit RSA keys for DNSSEC. Internally, we began discussing the root Zone Signing Key (ZSK) length increase in 2014. However, another important root zone change was looming on the horizon: changing the Key Signing Key (KSK).
A few months ago I published a blog post about Verisign’s plans to increase the strength of the Zone Signing Key (ZSK) for the root zone. I’m pleased to provide this update that we have started the process to pre-publish a 2048-bit ZSK in the root zone for the first time on Sept. 20. Following that, we will publish root zones with the larger key on Oct. 1, 2016.
To help understand how we arrived at this point, let’s take a look back.
For more than 30 years, the industry has used a service and protocol named WHOIS to access the data associated with domain name and internet address registration activities.
Do you need to find out who has registered a particular domain name? Use WHOIS. Do you want to see who an Internet Protocol (IP) address has been allocated to? Use WHOIS.
One of the most interesting and important changes to the internet’s domain name system (DNS) has been the introduction of the DNS Security Extensions (DNSSEC). These protocol extensions are designed to provide origin authentication for DNS data. In other words, when DNS data is digitally signed using DNSSEC, authenticity can be validated and any modifications detected.
A major milestone was achieved in mid-2010 when Verisign and the Internet Corporation for Assigned Names and Numbers (ICANN), in cooperation with the U.S. Department of Commerce, successfully deployed DNSSEC for the root zone. Following that point in time, it became possible for DNS resolvers and applications to validate signed DNS records using a single root zone trust anchor.
DNSSEC works by forming a chain-of-trust between the root (i.e., the aforementioned trust anchor) and a leaf node. If every node between the root and the leaf is properly signed, the leaf data is validated. However, as is generally the case with digital (and even physical) security, the chain is only as strong as its weakest link.
To strengthen the chain at the top of the DNS, Verisign is working to increase the strength of the root zone’s Zone Signing Key (ZSK), which is currently 1024-bit RSA, and will sign the root zone with 2048-bit RSA keys beginning Oct. 1, 2016.
One of the longstanding goals of network security design is to be able to prove that a system – any system – is secure.
Designers would like to be able to show that a system, properly implemented and operated, meets its objectives for confidentiality, integrity, availability and other attributes against the variety of threats the system may encounter.
A half century into the computing revolution, this goal remains elusive.
One reason for the shortcoming is theoretical: Computer scientists have made limited progress in proving lower bounds for the difficulty of solving the specific mathematical problems underlying most of today’s cryptography. Although those problems are widely believed to be hard, there’s no assurance that they must be so – and indeed it turns out that some of them may be quite easy to solve given the availability of a full-scale quantum computer.
Another reason is a quite practical one: Even given building blocks that offer a high level of security, designers, as well as implementers, may well put them together in unexpected ways that ultimately undermine the very goals they were supposed to achieve.
In 1905, philosopher George Santayana famously noted, “Those who cannot remember the past are condemned to repeat it.” When past attempts to resolve a challenge have failed, it makes sense to consider different approaches even if they seem controversial or otherwise at odds with maintaining the status quo. Such is the case with the opportunity to make real progress in addressing the many functional issues associated with WHOIS. We need to think differently.
The Domain Name System (DNS) offers ways to significantly strengthen the security of Internet applications via a new protocol called the DNS-based Authentication of Named Entities (DANE). One problem it helps to solve is how to easily find keys for end users and systems in a secure and scalable manner. It can also help to address well-known vulnerabilities in the public Certification Authority (CA) model. Applications today need to trust a large number of global CAs. There are no scoping or naming constraints for these CAs – each one can issue certificates for any server or client on the Internet, so the weakest CA can compromise the security of the whole system. As described later in this article, DANE can address this vulnerability.
Earlier this year, I wrote about a recent enhancement to privacy in the Domain Name System (DNS) called qname-minimization. Following the principle of minimum disclosure, this enhancement reduces the information content of a DNS query to the minimum necessary to get either an authoritative response from a name server, or a referral to another name server. This is some additional text.
In typical DNS deployments, queries sent to an authoritative name server originate at a recursive name server that acts on behalf of a community of users, for instance, employees at a company or subscribers at an Internet Service Provider (ISP). A recursive name server maintains a cache of previous responses, and only sends queries to an authoritative name server when it doesn’t have a recent response in its cache. As a result, DNS query traffic from a recursive name server to an authoritative name server corresponds to samples of a community’s browsing patterns. Therefore, qname-minimization may be an adequate starting point to address privacy concerns for these exchanges, both in terms of information available to outside parties and to the authoritative name server.